

Если вы ведете аналитику упоминаний вашего бренда или хоть раз пытались собирать данные и делать отчет по разрозненным критериям, то наверняка сталкивались с разметкой. Как правило, разметка зависит от вопросов, на которые вы хотите найти ответы.
Конечно, наиболее популярными остаются общие вопросы. Например, с помощью разметки вы можете сделать выборку с информацией о том, что пишут покупатели о ваших ценах или как отзываются о сотрудниках. Кроме того, можно проводить более глубокую и предметную аналитику. Представьте, что вы владелец продуктового магазина, недавно сменивший поставщика огурцов. Чтобы оценить качество этого продукта, достаточно с помощью разметки найти отзывы о конкретных огурцах в вашем конкретном магазине за конкретный период времени.
Поэтому отследить можно практически всё, главное, из общего потока собранных данных выделить те, которые имеют отношение к поставленным вопросам.
Самый простой и понятный подход — сформулировать цель (например, нам нужны отзывы про новые огурцы, т.е. пост про свежие огурцы) и критерии подобия (продолжая огуречные примеры: в постах, имеющих отношение к нашим магазинам, должно встречаться слово “огурец”, и/или название сорта огурцов, например “Кураж”, “Бакинские”, но при этом не нужны консервированные “Дядя Ваня”); если собранная информация удовлетворяет критерию — поставить метку.
После разметки данных уже можно визуализировать статистику, искать инсайты, делать анализ и выводы. Такой подход работает и при анализе данных из соцмедиа.
Характеристик и меток может быть много. Какие-то легко определить, например, когда в тексте есть явное упоминание уникального названия бренда. Но чаще определение размыто — оно понятно на интуитивном уровне, но сложно в описаниях, например, это касается ответа на вопрос “Что пишут о нашем персонале?”.
Когда массив данных содержит несколько десятков записей, или даже сотен, то это, конечно, не проблема. Один раз весь контент можно изучить самостоятельно, разметить «руками» и сделать анализ.
Однако разметка становится проблемой, если данных много или когда анализ необходимо делать регулярно. В таком случае неизбежны ошибки, ведь большое количество размечаемых постов в течение долгого времени создают монотонность работы. При этом её эффективность падает, а цена неоправданно возрастает.
Кстати, мы провели замеры и определили среднее количество публикаций, которое может разметить один сотрудник за восьмичасовой рабочий день, работая в системе Angry Analytics. Мы понимаем, что может быть много факторов, влияющих на количественный показатель работы, начиная от других текущих задач и заканчивая общим состоянием компьютера. Однако, на наш взгляд, при планировании бюджета на разметку данных ручным способом разумно ориентироваться на 2-4 тысячи публикаций в день.
Оптимизация разметки данных
В системе Angry Analytics мы создали ряд «умных» модулей и ручных инструментов для автоматизации разметки постов по следующим критериям:
- геопривязка к филиалу заказчика;
- эмоциональная окраска сообщения (куда же без неё);
- релевантность;
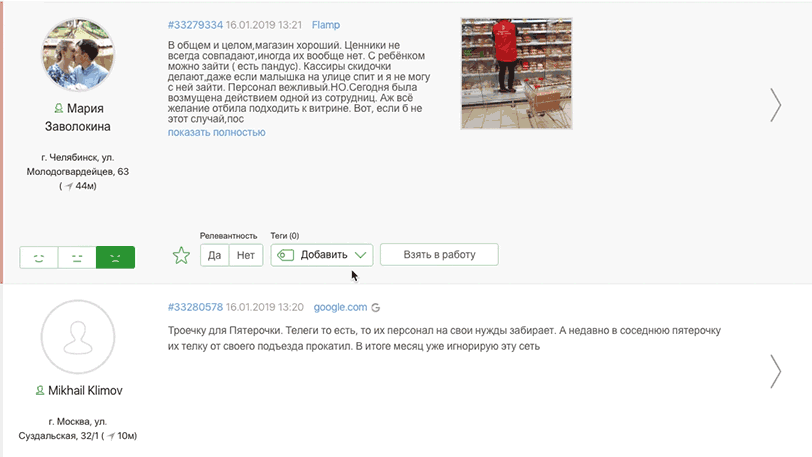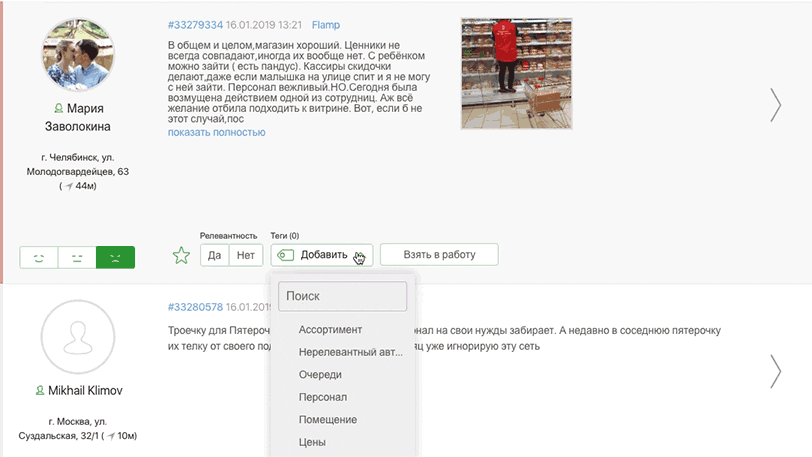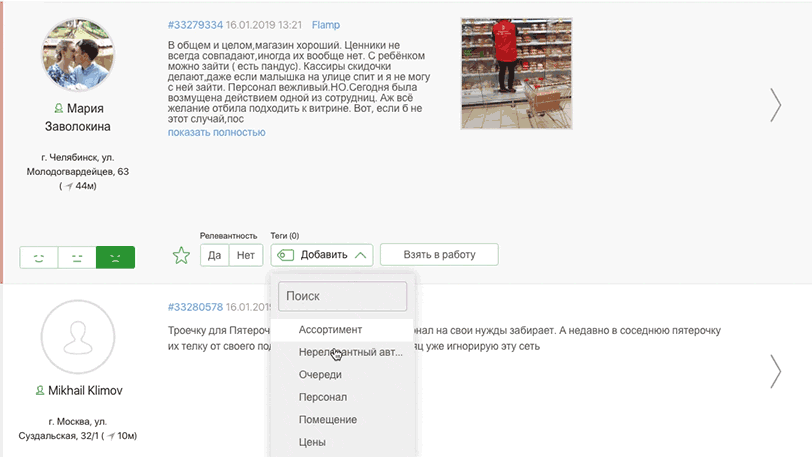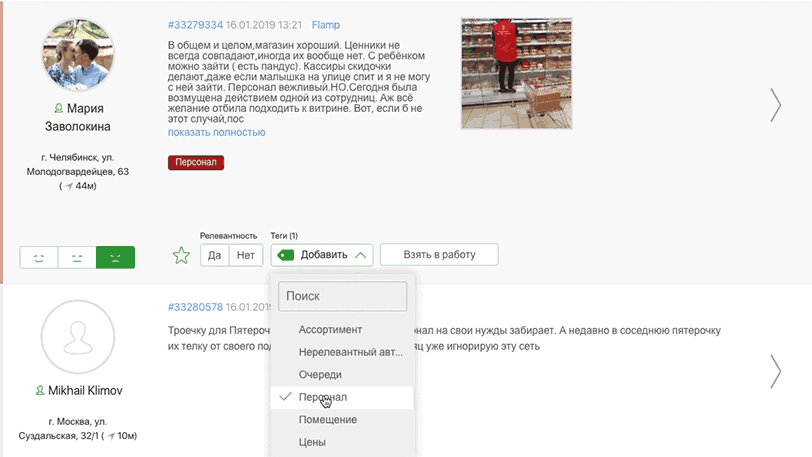
- теги;
- персонализированные флаги.
Каждый инструмент и модуль уникален и успешно решает определенную задачу.
Сейчас мы рассмотрим нюансы настройки тегов для автотегирования и посмотрим, как это может облегчить нам работу.
Тег поста — это словесная метка поста, которая, как правило, содержит в своем названии смысл критерия установки.
Автотегирование с помощью паттернов
Angry Analytics позволяет сократить расходы и время на разметку постов с помощью автоматизации установки тегов по заранее известным паттернам.
Паттерн — это шаблон, по которому система проверяет, подходит ли пост под условие установки тега
Общий кейс
Возьмём самый простой вариант — необходимо тегировать посты, в которых есть упоминание определенного слова или набора слов.
Например, нам нужны все посты, где речь идет о цене товара. Как правило, такие посты содержат в себе слово «цена». Паттерн для этого случая будет эквивалентен самому слову, и в настройках будет достаточно указать слово «цена«.
В русском языке есть склонения, форма единственного и множественного числа, а значит, под условие должны попадать слова «цены«, «цене«, «цену» и т.п. Все эти слова объединяет общий корень «цен». Таким образом, нам нужен паттерн, под который подойдут все варианты — это слова, начинающиеся с набора букв «цен».
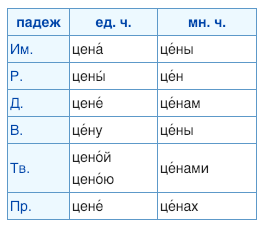
В настройках тега можно перечислить все словоформы, а можно воспользоваться простым паттерном. В примере со словом «цена» достаточно указать «цен.*» и это полностью заменит возможные варианты.
Такой простой вариант хорошо подходит для длинных и уникальных слов.
Делаем уточнения
Описанный выше вариант «цен.*» будет помечать нерелевантные по смыслу посты, содержащие слова: «центр», «центнер», «процент», «доцент» и т.д.
Для того чтобы не захватывались слова с приставкой, достаточно указать ограничитель «\b«, а для исключения ложного срабатывания на не релевантные посты достаточно перечислить только подходящие окончания через логический оператор. Так мы получим простую конструкцию:
\bцен(а|ы|е|ам|у|ой|ою|ами|ах)
Кейс с клиентом
Сфера деятельности одного из наших клиентов такова, что в отзывах очень часто пишут о сотрудниках, упоминая их ФИО.
В оптимизации задачи сбора этой информации тоже помогают паттерны автотегов. Мы учитываем несколько вариантов написания полного и краткого варианта имени, перестановки фамилии, имени, отчества, а также возможные ошибки в написании.
В результате, клиент в автоматическом режиме получает актуальный ТОП своих сотрудников согласно отзывам.
В чем трюки-хаки?
По нашему опыту, филиальная сеть магазинов розничной торговли может собирать несколько десятков тысяч постов и отзывов в месяц.
Для того чтобы иметь оперативную актуальную информацию при разметке в ручном режиме, необходим как минимум один штатный специалист на полный день. Автоматическая разметка настраивается за несколько минут или часов, т.е. экономия бюджета — зарплата целого штатного сотрудника!
Использование автоматической разметки данных автотегами позволяет сэкономить бюджет на подготовку аналитики в несколько раз засчёт сокращения издержек на разметку.
Даже если случай разметки достаточно сложный, чтобы исключить весомую погрешность, мы всё равно экономим очень много времени. Ведь тогда аналитику необходимо будет проверить только те данные, которые уже размечены автоматически и устранить ошибочно поставленные теги. А это, как правило, всего лишь единицы процентов от общего собранного контента, т.е. в 10-20 раз меньше.
Ещё магии?
И в завершение — динамика негативных постов о персонале в популярной розничной сети за 5 дней в январе. Создана за несколько секунд на основе автотегов по паттернам.
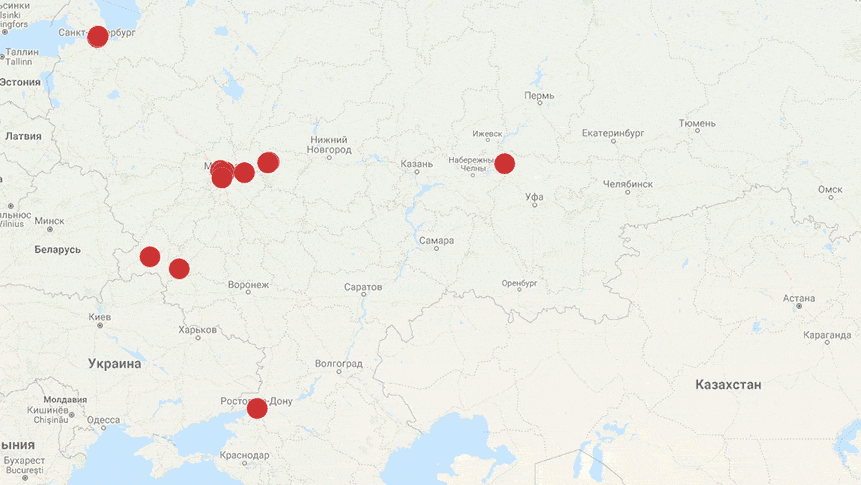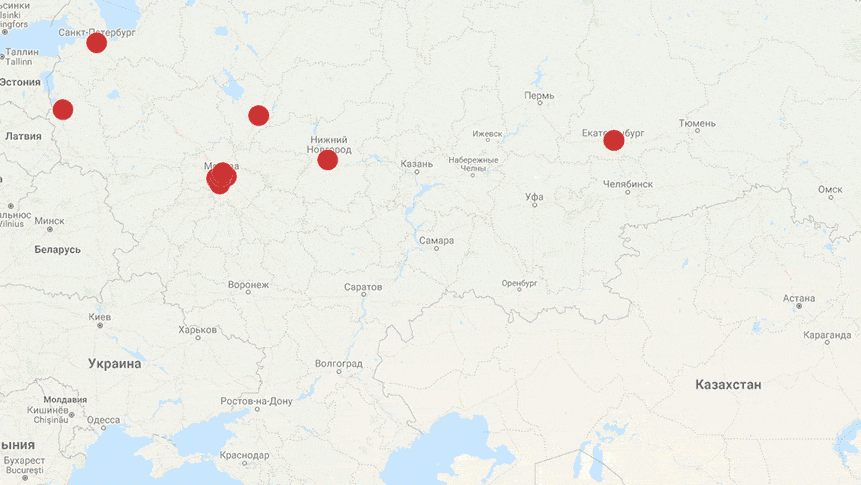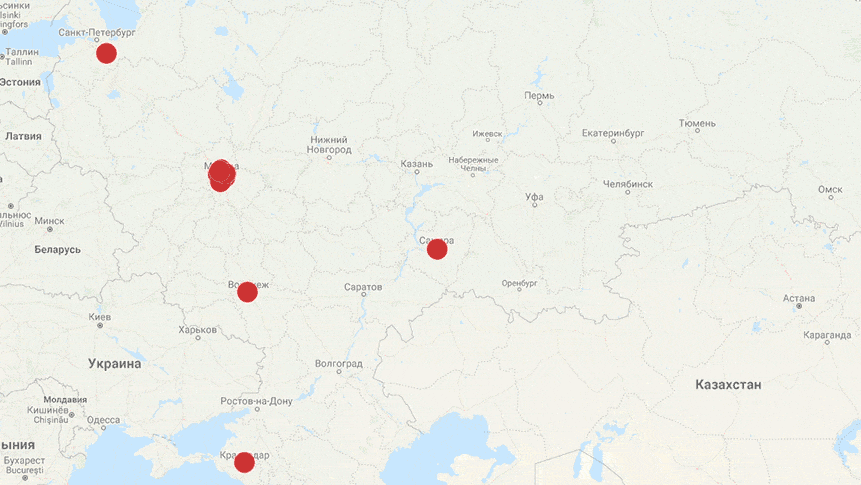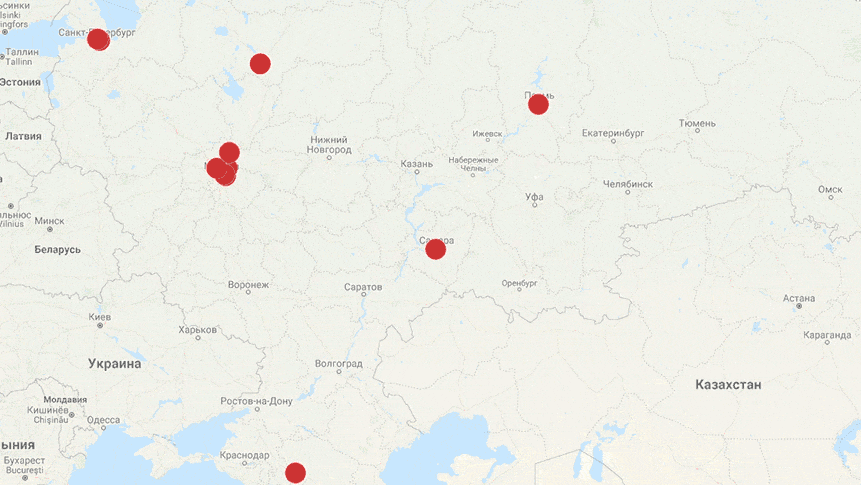
В следующих постах рассмотрим нюансы разметки по другим критериям. Cледите за новостями Angry Analyics.